昨晚发布开源的llama3
| 0人浏览 | 2024-04-19 07:52 |
| 0人浏览 | 2024-04-19 07:52 |
meta 提前发布了llama3,预期5-6月发布的。但现在又无法点击了。
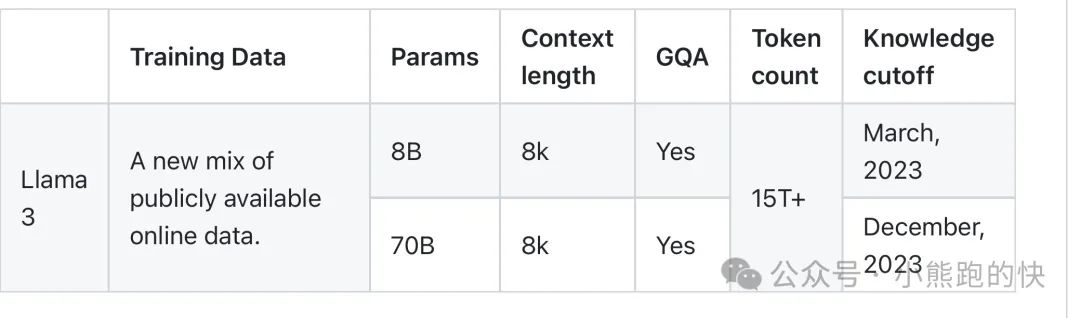
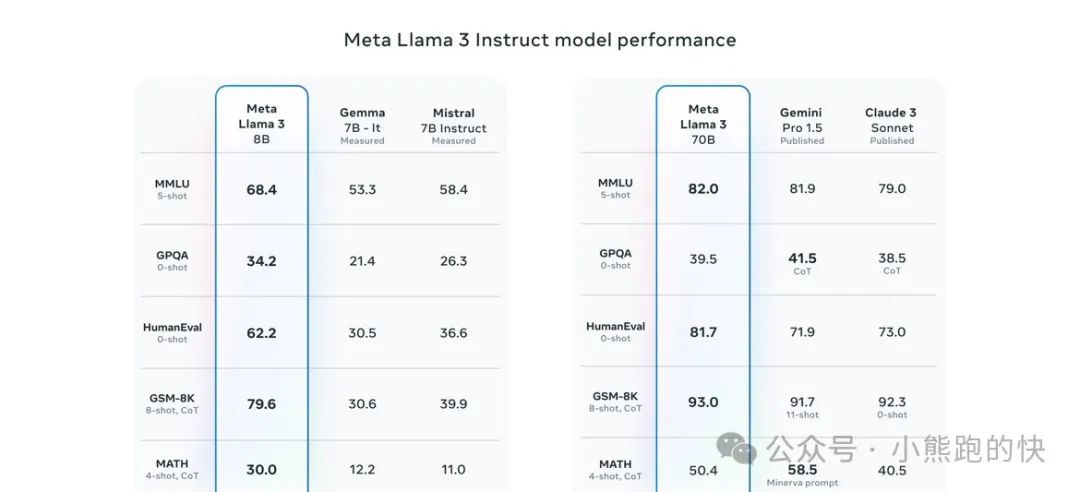
Meta 开发并发布了 Meta Llama 3 系列大型语言模型 (LLM),8 B和 70B 大小的生成文本模型。 Llama 3 指令调整模型针对对话用例进行了优化,并且在常见行业基准上优于许多可用的开源聊天模型。
输入模型仅输入文本。输出模型仅生成文本和代码。
没有多模态 图片输入和输出!
社区里面公告了 大家可以拿来微调(只允许英语)。开源!
公告了训练量 h100 770w个训练小时。一万颗一个月的样子。
训练数据超过15 万亿token进行了预训练。微调数据包括公开可用的指令数据集,以及超过 1000 万个人工注释的示例。
对降低推理成本的一些思考!Llama 3 的开发过程中,对缩放行为进行了一些新的观察。例如,虽然 8B 参数模型的 Chinchilla 最佳训练计算量对应于约 200B 个标记,但我们发现即使在模型建立之后,模型性能仍在继续提高接受了两个数量级以上的数据训练。在我们对多达 15T tonken进行训练后,我们的 8B 和 70B 参数模型都继续以对数线性方式改进。较大的模型可以用较少的训练计算来匹配这些较小模型的性能,但较小的模型通常是首选,因为它们在推理过程中效率更高。
三种类型的并行化:数据并行化、模型并行化和管道并行化。当同时在 16K GPU 上进行训练时,我们最高效的实现可实现每个 GPU 超过 400 TFLOPS 的计算利用率。我们在两个定制的 24K GPU 集群上进行了训练。为了最大限度地延长 GPU 的正常运行时间,我们开发了一种先进的新训练堆栈,可以自动执行错误检测、处理和维护。我们还极大地改进了硬件可靠性和静默数据损坏检测机制,并且开发了新的可扩展存储系统,以减少检查点和回滚的开销。这些改进使总体有效培训时间超过 95%。综合起来,这些改进使 Llama 3 的训练效率比 Llama 2 提高了约三倍。
之后会发布更大的一个400B 参数模型。
海外评述:1)上下文8k似乎太短了,这明显不及其他模型;
2)大家最好奇它的龙猫缩放定律,能不能公布 训练数据量对最后评分的影响?目前看来训练数据量越大 分数越高。